A guide to
Kode basics
(by Tored)
Introduction
What even is Kode? If you've used Kustom apps before, you probably are familiar with the formula editor window. Everything you write in the Formula Editor field is Kode.
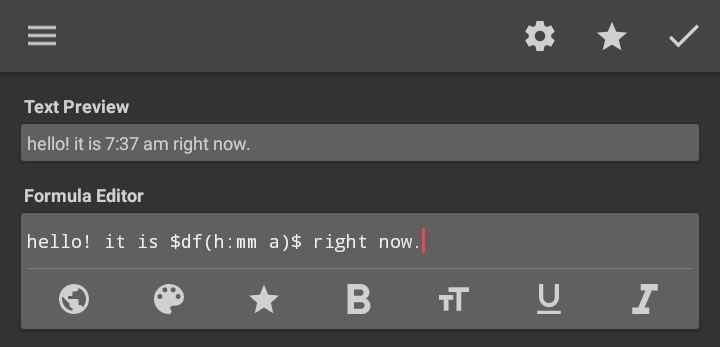
By default, what you write in the formula editor is displayed as-is (plain text).
However, anything you put between dollar signs ($) will be evaluated.
Evaluation means that Kustom will take what you wrote, interpret it as a set of commands telling it what to do, and then produce a result (output) that will then be displayed (printed) instead of the entire text between dollar signs.
Important notes regarding this guide
A quick note for the very start - experimenting and testing stuff for yourself is highly encouraged. If you encounter something you don't get, try doing it in the editor and seeing how it works in practice.
If you want to test the examples for yourself:
- You can double-tap/double-click any example box to copy its contents to clipboard,
-
For readability, I won't use dollar signs where there's no need to combine Kode and normal text.
Don't forget to wrap anything you want evaluated in dollar signs (
$).
There is a light/dark theme switch available in the sidebar. By default, the guide uses your system's theme.
If you'd like to refer someone to a section of this guide:
- Each section title is also a link to that section,
- Long press/right click the section title and then use "copy link address" to get a link that will open the guide on that section.
Because your browser supports service workers, this page will be available even if you visit it while offline.
This guide is also a PWA that can be installed like an app on your device. You can install it from your browser's menu, or by click the button below:
With all that out of the way, let's talk about how Kustom transforms your Kode text into a result value.
Have fun!
Values and operators
Numbers and math
Let's start with introducing basic Kode syntax elements with an example:
1 + 2
This entire example is a mathematical expression, consisting of two values and one operator. We can write longer expressions by adding more numbers and operators:
6
+
5
-
4
*
3
/
2
^
1
The table below shows all mathematical operators available in Kustom:
| Symbol | Name | Example | Output |
|---|---|---|---|
+ |
Addition | 3 + 2 |
5 |
- |
Subtraction | 3 - 2 |
1 |
* |
Multiplication | 3 * 2 |
6 |
/ |
Division | 3 / 2 |
1.5 |
% |
Modulo | 3 % 2 |
1 |
^ |
Exponentiation | 3 ^ 2 |
9 |
The order of operations in Kustom follows the standard mathematical order of operations.
In this example, 2 ^ 1 gets evaluated first. Then the output of that evaluation gets put in
place
of 2 ^ 1, and the formula is evaluated further:
6 + 5 - 4 * 3 / 2 ^ 1
6 + 5 - 4 * 3 / 2
Next there are two operators of equal "weight", so the leftmost one is evaluated first:
6 + 5 - 4 * 3 / 2
6 + 5 - 12 / 2
Then division:
6 + 5 - 12 / 2
6 + 5 - 6
Finally, the two remaining operators again get evaluated from left to right:
6 + 5 - 6
11 - 6
11 - 6
5
And we arrive at an output:
5
Note that for certain calculations the output might not be 100% accurate due to rounding errors - a number inside your phone/computer can only store so many decimal places.
You can influence the order in which operators are evaluated using parentheses:
3 * (2 + 1)
Because of the parentheses, addition gets evaluated before multiplication:
3 * (2 + 1)
3 * 3
3 * 3
9
9
Strings (text values)
Quoted strings
Text values, often referred to as strings, are used very, very frequently. To add one to your formula, wrap some text in quotation marks ("), which I'll also refer to as doublequotes. The quotation marks won't be part of the output.
"I am a quoted string"
I am a quoted string
Strings have one operator that uses the same symbol as addition: + (concatenation).
It joins two strings together:
"abc"
+
"def"
abcdef
Expressions inside quoted strings are not evaluated:
"2 + 1"
2 + 1
A common misconception I've seen is trying to use $ to evaluate a part of a string.
Instead, calculate the result separately and concatenate it with the other parts of the string.
"2 + 2 is $2 + 2$!"
2 + 2 is $2 + 2$!
"2 + 2 is "
+
(2 + 2)
+
"!"
2 + 2 is 4!
Quoteless strings
If you add text to a formula without using doublequotes, Kustom will interpret it as text:
I am a quoteless string
I am a quoteless string
Quoteless strings cannot contain special characters, like operator symbols, dollar signs or parentheses:
$Please give me $1000$
In those cases, quoted strings should be used:
"Please give me $1000"
They can contain whitespace (like spaces or even new line characters), but any whitespace at the beginning or end will be trimmed out:
first string + second string
first stringsecond string
Notice that the spaces around the + operator are not present in the output, but the spaces inside the quoteless strings are preserved.
If you are unsure which type of string to use, I'd recommend only using quoteless strings when the text you're writing is a constant value Kustom expects,
like ALWAYS or NEVER for visibility, or when it's a function mode like low or up (more on those later).
The default string mode of operators
If you try using mathematical operators on text, you might notice something weird happening:
"a" * "b"
a*b
A very similar result occurs with most operators in Kode, except for ones specifically made to work differently with strings. Its main purpose is to allow strings containing operator characters to remain without doublequotes. You might have encountered it (and not noticed) when writing things like icon names:
weather-sunny
weather-sunny
Notice that the example above is two quoteless strings and the subtraction operator, and not one continuous long string. This becomes far more obvious if you choose to quote the strings and add whitespace, which does not change the output:
"weather" - "sunny"
weather-sunny
This behavior is present for all operators, except ones listed in the table below:
| Operator | String mode |
|---|---|
+ |
Concatenation |
= |
Check if two strings are the same |
!= |
Check if two strings are different |
~= |
Check if a string contains another string/regex test |
Note on Combining strings and numbers
Kustom converts value types from one to another on the fly.
Because of that, any string that can be parsed as a number (decimals like "5.23" count as numbers too!) will be converted to a number when using the + operator (and other operators too), as well as before being passed to (most) functions (more on those later).
That parsed number will be used instead of the original string.
" 00002.0000 " + abc
2abc
This can lead to problems when trying to preserve things like leading zeroes or a trailing decimal point, or trying to concatenate numbers instead of adding them. A workaround for this issue is presented in the "Additional tips & tricks" section at the end of this guide.
Functions
Introduction to functions
Functions are the main part of Kode. Some of them can be used to get information, like the current time, weather, system information, calendar events and much more. Other functions can be used to perform mathematical calculations or transform text. Asking the function to do something is called "calling" the function. The basic structure of a function call is as follows:
-
The name of the function to be called.
In Kode, functions have two letter names that are usually short for the full name of the function. For example,dfis short for "Date Format", whiletcis short for "Text Converter". -
((an opening parenthesis), -
Arguments separated by commas (
,) -
)(a closing parenthesis),
tc(low, "Make Me Lowercase")
A function can also only take one argument:
ai(isday)
Or not take any:
dp()
Arguments can be expressions with values and operators or other function calls - anything that returns a value.
Before a function is evaluated, all its arguments have to be evaluated.
Consider this example of calling tc() (Text Converter), with one of the arguments being a concatenation of two strings:
tc(low, "Make Me " + "Lowercase")
In this example, the concatenation gets evaluated first:
tc(low, "Make Me " + "Lowercase")
tc(low, "Make Me Lowercase")
Now, the function can take both arguments and turn them into a result. In this case, the first argument is a mode string, which tells the function what to do with the other argument.
The low mode of tc() converts the string given in the second argument to lowercase:
tc(low, "Make Me Lowercase")
"make me lowercase"
make me lowercase
If we instead changed the mode argument to up, tc() would instead convert the string to uppercase:
tc(up, "Make Me Lowercase")
"MAKE ME LOWERCASE"
MAKE ME LOWERCASE
You can also use another function call as an argument. Because arguments need to be evaluated before the function call, these calls will be evaluated from the inside out.
In this example, mi() stands for Music Info, and mode title returns the title of the currently playing music.
tc(low, mi(title))
The "deeper" function gets evaluated first:
tc(low, mi(title))
tc(low, "Music Title")
Now the tc() call can be evaluated:
tc(low, "Music Title")
"music title"
music title
You can also combine function calls with operators:
tc(low, mi(artist) + " - " + mi(title))
Before a + (concatenation) operation can be evaluated, both its sides need to be evaluated.
This means that in this example, mi(artist) (returns the artist behind currently playing music)
will get evaluated first:
tc(low, mi(artist) + " - " + mi(title))
tc(low, "Artist Name" + " - " + mi(title))
After that, the first concatenation can be evaluated:
tc(low, "Artist Name" + " - " + mi(title))
tc(low, "Artist Name - " + mi(title))
Then mi(title) and the second concatenation:
tc(low, "Artist Name - " + mi(title))
tc(low, "Artist Name - " + "Music Title")
tc(low, "Artist Name - " + "Music Title")
tc(low, "Artist Name - Music Title")
Finally, the tc() call can get evaluated:
tc(low, "Artist Name - Music Title")
"artist name - music title"
artist name - music title
Keep in mind that all the problems you'd see with strings containing numbers also apply to function return values. If you try to concatenate a function's result that is a number and a string number, you'll get addition instead.
Note on Regex (regular expressions)
While Regex/regular expressions might sound scary if you haven't used them before, they are a very powerful tool that is worth learning. They are not used only in Kustom, you can make use of them in other tools and programming languages for advanced text searching and replacing.
A regular expression is a string consisting of regular characters and special characters that can match different characters or multiple characters, called a pattern.
Regular expressions are used to search for a pattern in a
In Kustom, tc() has a mode that allows you to make use of regular expressions - tc(reg). This function accepts 3 arguments after the mode:
tc(reg, string, pattern, replacement)
If you don't want to learn regex, please just note that you can use tc(reg) to simply replace all occurences of a string with another string:
tc(reg, "I like trains", "like", "don't like")
I don't like trains
Here is an example of using a pattern to remove everything after a dash by replacing it with an empty string:
tc(reg, "This part is wanted - this part isn't", " -.*", "")
This part is wanted
Here is what the pattern does:
-
.*matches any character (.) 0 or more times (*)
Note that in the replacement string, $0 can be used to refer to the entire match, and $1,
$2, …, $9 to groups 1-9 of the match.
I won't go in depth about regex here, as it'd be repeating work already done better elsewhere. I'll instead provide you some links if you'd like to learn, but don't know where to begin:
- RegexOne can help you master the basics by giving you exercises as you go,
- Regex101 is a great tool to build patterns with, letting you test on any text you want, as well as highlighting what your pattern selects and why,
- Regexr is a similar tool, but with a different user interface,
- AutoRegex is a tool that attempts to translate english into a regex pattern. It is not 100% accurate all the time, but it might help you learn.
Doing A or B depending on X
Introduction to boolean values
A boolean value is either true (represented as 1 in Kustom)
or false (represented as 0 in Kustom).
In most cases, we'll obtain a boolean value from a function like ai(isday)
(1 when it is day, 0 otherwise)
or si(locked) (1 when the phone is locked, 0 otherwise),
or, alternatively, from comparing two values using one of the comparison operators listed below:
| Symbol | Name | Returns 1 |
Returns 0 |
|---|---|---|---|
= |
Equal | 1 = 1 |
1 = 2 |
!= |
Not equal | 1 != 2 |
1 != 1 |
< |
Less than | 1 < 2 |
2 < 1 |
> |
Greater than | 2 > 1 |
1 > 2 |
<= |
Less than or equal | 1 <= 1 |
2 <= 1 |
>= |
Greater than or equal | 1 >= 1 |
1 >= 2 |
If you try to compare text and a number, Kustom will try its best to convert the text to a number before
comparing them.
That means that a number is equal to its string representation, as far as Kustom is concerned.
All following examples will return 1 (true):
"2" = 2
"00002" = 2
"2.0000" = 2
" 00002.0000 " = 2
Conditions and if()
if() is a very frequently used function that is closely connected to booleans.
Unlike tf() or mi(), it doesn't take a mode argument. The most basic version of an if() call looks like this:
if([condition], [value if condition true])
The function will return the second argument if the boolean given to it in the first argument is 1 (true),
Otherwise, the function will return seemingly nothing - an empty string, which can be written as two quotation marks next to one another ("").
In this example, 2 = 2 first evaluates to 1 (true):
if(2 = 2, "Reality is still intact")
if(1, "Reality is still intact")
Since the condition argument is 1 (true), if() will return the value of the second argument:
Reality is still intact
If a third argument is provided to the call, it'll be returned when the condition is 0 (false):
if([condition], [value if condition true], [value if condition false])
if(1 = 2, "Weird", "Normal")
if(0, "Weird", "Normal")
Normal
It's worth noting that empty strings ("") are considered false by if(), while any other value will be considered true:
if("", "true", "false")
false
if("text", "true", "false")
true
if() calls can be extended with more pairs of condition-value arguments:
if(1 = 2, "first", 2 = 2, "second", 3 = 3, "third", "none")
The function will go through each condition argument in order until it finds one that is true. If a true condition argument is found, the value from its pair is returned:
if(0,
"first",
1,
"second",
1,
"third",
"none")
second
If all conditions turn out to be false, if() will return the last argument:
if(0,
"first",
0,
"second",
0,
"third",
"none")
none
If the last argument isn't present, an empty string ("") will be returned:
if(0,
"first",
0,
"second",
0,
"third")
Combining conditions using logical operators
Sometimes one condition is not enough and you need to combine multiple conditions.
Maybe your battery icon should only be coloured red if the battery is below 15% and the battery is discharging.
Maybe you'd like to display "Weekend!" when it is Saturday or Sunday.
Kode has two operators for combining boolean values, logical AND, represented by an ampersand (&) and logical OR, represented by a pipe (|).
AND only returns true when values on both sides of it are true.
OR returns true when one or both of the values are true.
The table below illustrates all the different combinations of boolean inputs and what combining them with AND and OR will result in.
A |
B |
A & B |
A | B |
|---|---|---|---|
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
To illustrate how & and | can be used in conjunction with if(), let's write formulas for the two examples I mentioned at the start of this section.
The first example was coloring a battery icon red if the battery is below 15% and the battery is discharging.
-
bi(level)returns the current battery level (from0to100), -
bi(charging)returns1if the phone is charging and0otherwise, -
#ff0000is the color hex for red,#ffffffis the color hex for white.
if(bi(level) < 15 & bi(charging) = 0, #ff0000, #ffffff)
if(bi(level) < 15 & bi(charging) = 0, #ff0000, #ffffff)
if(10 < 15 & 1 = 0, #ff0000, #ffffff)
if(10 < 15 & 1 = 0, #ff0000, #ffffff)
if(1 & 1, #ff0000, #ffffff)
if(1 & 1, #ff0000, #ffffff)
if(1, #ff0000, #ffffff)
#ff0000
The second example was displaying "Weekend!" when it is Saturday or Sunday.
-
df(f)returns the current weekday (Monday being1and Sunday being7), - assume it is Saturday.
if(df(f) = 6 | df(f) = 7, "Weekend!")
if(df(f) = 6 | df(f) = 7, "Weekend!")
if(6 = 6 | 6 = 7, "Weekend!")
if(6 = 6
|
6 = 7, "Weekend!")
if(1 | 0, "Weekend!")
if(1 | 0, "Weekend!")
if(1, "Weekend!")
Weekend!
There are some important differences in how if() treats values other than 1 and 0
and how & and | do it.
& and | have a default string mode like described in "The default string mode of operators".
For the following examples, assume no music player has been opened, so mi(artist) and mi(title) are empty strings ("").
Trying to check if two strings are empty is not possible like this:
mi(artist) & mi(title)
&
Instead, a comparison needs to an empty string needs to be made explicitly:
mi(artist) = ""
&
mi(title) = ""
1
&
1
1
If the arguments are not strings, but numbers, any number given to & and | that isn't a 1 will be
treated as false.
5 | 0
0
Logical operator precedence
You might expect & to have a higher precedence than |, or in other words, for ANDs to evaluate before ORs - especially if you are already familiar with other programming languages.
Those operators have the same precedence in kode, which means they will be evaluated left to right, unless parentheses are introduced to change the order of evaluation.
To illustrate where this is important, let's check if the clock's hour hand is nearly horizontal, by checking if the current hour is between 2 and 4 or 8 and 10:
if(
df(h) >= 2 & df(h) <= 4 | df(h) >= 8 & df(h) <= 10,
"Clock hour hand is almost horizontal"
)
if(
3 >= 2 & 3 <= 4 | 3 >= 8 & 3 <= 10,
"Clock hour hand is almost horizontal"
)
3 >= 2 & 3 <= 4 | 3 >= 8 & 3 <= 10
1 & 1 | 0 & 0
1 & 1 | 0 & 0
1 | 0 & 0
1 | 0 & 0
1 & 0
1 & 0
0
To fix this issue, each pair should be wrapped in parentheses:
(3 >= 2 & 3 <= 4) | (3 >= 8 & 3 <= 10)
1 | 0
1 | 0
1
Clock hour hand is almost horizontal
Inverting booleans
Kustom lacks a dedicated operator for inverting booleans (returning 1 when given 0 and vice versa).
It is possible to compare a boolean to 0 to achieve the same result (assume it is day and so ai(isday) returns 1):
if(ai(isday) = 0, night, day)
if(1 = 0, night, day)
if(1 = 0, night, day)
if(0, night, day)
day
If you want to invert the result of a comparison, you can also invert its operator, by for example swapping = with !=, or > with <=.
Finally, you can also invert the result of if() calls by simply swapping the second and third argument.
Contains/Regex test: ~=
This operator got its own separate mention, because it's distinct from the other comparison operators, but it still returns a boolean. In its most basic form, this operator checks whether the left hand side string has the right hand side string inside it, which can be read as "check if A contains B".
abc ~= a
1
abc ~= d
0
Note for advanced users: this operator tests if the left argument matches any part of the regex expression
provided as the right argument. It is possible to use it to check if the entire left argument matches the
expression by having the expression start with ^ (match start of string) and end with
$ (match end of string).
Writing cleaner formulas with lv()
If you've written any kind of longer formula before, you might have ran into something like this:
"I've written this lengthy bit of Kode that gets the value I need, but I need to use it in multiple places, so now I had to copy it everywhere, and now fixing the formula is a nightmare."
Recently at the time of writing, a new function called lv() (Local Variable, requested by yours truly) was introduced.
This function can be used to solve the problem described above.
The basic usage of lv() starts by calling it with two arguments to store a value in a local variable under a given name:
lv(name, value)
Calling lv() with two arguments always returns an empty string.
This is because it is meant to be used within a formula, but without changing the result on its own.
To later retrieve a value stored in a local variable, you can call lv() with only one argument, the name of the variable:
lv(name)
value
When using this syntax, if a variable isn't found, a warning will show up and an empty string ("") will be returned.
Alternatively, you can use the new # syntax. Kustom will try to find a local variable for any quoted or unquoted string starting with #:
#name
value
When using this syntax, if a variable isn't found, Kustom will simply return the string as-is:
#name2
#name2
Let's use an example to illustrate how lv() can help you write cleaner formulas.
For this example, let's say we've written a formula that loads a list of quotes from a text file, and we would now like to display a random quote (line) from that list:
wg("file:///sdcard/quotes.txt", raw)
"I like trains" - Albert Einstein
"This sentence is false" - Archimedes
...
We can use tc(split) to split the text into a list of lines and take a line at an index.
The index of the line will be random, but it needs to an index of a line, and not just any random number.
tc(lines) can be used to obtain the number of lines in a given string.
Then, mu(rnd) can be used to get a random number between 0 and the maximum index, which is number of lines - 1.
If all of that is combined into a formula, it will look like this:
tc(split, wg("file:///sdcard/quotes.txt", raw)), mu(rnd, tc(lines, wg("file:///sdcard/quotes.txt", raw)) - 1))
"I like trains" - Albert Einstein
Not only is this formula long and hard to read, if we now wanted to change the path to the file with the quotes, we would have to change it in two different places. It's not hard to imagine formulas like this getting out of hand very quickly, as the number of different values needing to be copied and pasted increases.
To clean this up, let's first place the quotes into a local variable, and then use that variable in the formula:
lv(quotes, wg("file:///sdcard/quotes.txt", raw)) +
tc(split, #quotes, mu(rnd, tc(lines, #quotes) - 1))
"I like trains" - Albert Einstein
This formula takes advantage of the fact that lv() returns an empty string and uses + to concatenate that empty string to the actual result of the formula.
The part actually generating the result has gotten much shorter, and if the path to the file changes, it only needs to be changed in one place.
You could also use lv() to split calculations into multiple steps.
Here, two sides of a right triangle are given.
The formula calculates the third side using the Pythagorean theorem and stores that in another variable.
Finally, it uses the three variables to return the perimeter of the triangle:
lv(a, 245) +
lv(b, 310) +
lv(c, mu(sqrt, #a ^ 2 + #b ^ 2)) +
#a + #b + #c
Even with basic usage, lv() is a powerful tool that can help you make even complex formulas readable, debuggable and modifiable.
More value types
Date & time
Date & time is another value type in Kustom. It holds information about a specific point in time, down to a second. A date & time comprises of the following components:
y- YearM- Monthd- Dayh- Hourm- Minutes- Second
Displaying a date & time using df()
df() (Date Format) is a function that can be used to display data from a datetime value in any format you
want.
In its simplest form, it takes one text argument, that being the format, and displays (prints) the current date &
time in that format:
df("yyyy-MM-dd hh:mm:ss")
2022-07-11 01:33:59
Using the same token letter multiple times will cause the value to be padded with zeroes to the left until it reaches the same number of characters as the number of letters:
df(dddddddd)
00000012
Other tokens can also print a textual representation of the given component:
df("EEEE, d MMM yyyy")
") around the format. This is necessary, because the format includes a comma (,), which is a special character in kode.
Friday, 11 Nov 2022
Check out the official df() function documentation page for all the different tokens you can use.
If you try to add a description after a token, you might run into a problem like this:
df("m minutes")
34 34inute28
The letters m and s in the
word minutes were interpreted as tokens and, consequently, replaced by numbers.
To prevent that from happening, you can wrap what you want to be just text in singlequotes ('):
df("m 'minutes'")
34 minutes
A token deserving a separate mention is H, which prints the current hour in a 24-hour format.
This is useful for making time comparisons - with just h, you can't tell the difference between 1 AM and 1 PM, for example.
Here's an example that returns:
- "morning" until 12 AM,
- "afternoon" after 12 AM and until 6:30 PM,
- "evening" after 6:30 PM and until 9 PM,
- "night" after 9 PM:
if(
df(Hmm) <= 1200,
morning,
df(Hmm) <= 1830,
afternoon
df(Hmm) <= 2100,
evening,
night
)
If a date & time value is given as the second argument to df(), it'll be used instead of
the current date & time.
In this example, the start date & time of the first upcoming calendar event is formatted and printed:
df("yyyy-MM-ss hh:mm:ss a", ci(start, 0))
2022-08-11 08:00:00 AM
The Kustom date & time format
dp() is a function that can be used to create datetime values from text or numbers.
When no arguments are given, it returns the current date and time as a datetime value, in the Kustom date format:
2019ymeans that the year is 2019,10Mmeans that the month is 10,24mmeans that it's the 24th minute etc.
dp()
2019y10M11d15h24m28s
Date & time values written in this string format can not only be passed to dp() to get a date & time value, but also directly to functions expecting a date & time argument, like df():
df("yyyy-MM-dd hh:mm:ss a",
2022y11M10d13h13m41s)
2022-11-10
01:13:41
PM
The Kustom date & time format also includes an easy way to add to or subtract from a date & time value.
Any amount of time you specify after an a will be added to the date,
and anything after an r will be subtracted (which you can remember as add/remove).
In this example, I'll specify a date & time using the Kustom format, and then add 1 day, 2 hours, 3 minutes and 4 seconds to it:
dp(2019y10M4d10h24m32sa1d2h3m4s)
2019y10M5d12h27m36s
In this example, I'll again specify a date & time, and then subtract 1 day, 2 hours, 3 minutes and 4 seconds from it:
dp(2019y10M4d10h24m32sr1d2h3m4s)
2019y10M3d8h21m28s
You can also combine both adding and subtracting - in this example I'll both add 1 day and 4 seconds and subtract 2 hours and 3 minutes.
dp(2019y10M4d10h24m32sa1d4sr2h3m)
2019y10M5d10h21m36s
The way the Kustom date & time format works is it starts off with the current date & time value and then overwrites/adds to/subtracts from specific components of that date & time value.
As an example of combining these mechanics, let's consider using 0h0m0sa1d to get tomorrow's midnight:
1. This results in the date & time of tomorrow's midnight:
- At the start, Year, Month, Day, Hour, Minute and Second are copied from the current date & time,
-
0h,0m,0s- Hours, Minutes and Seconds are set to0, -
a1d- Day is increased by1.
- Year, Month and Day specifying tomorrow as the date,
- Hours, Minutes and Seconds specifying midnight (00:00:00) as the time.
If you only use addition and/or subtraction, you'll get a datetime relative to the current date and time.
For example, using just a1d or r1d will give you the same time as right
now, but the date for tomorrow or yesterday respectively.
Some functions ignore the time portion of the date & time arguments they are given.
For example, ci(title, 0, a1d) gets the title of the first calendar event for tomorrow.
The time portion of the date resulting from a1d is ignored, and only the date portion is used to determine what day to get the first calendar event for.
Timespan
Timespan is a different value type than datetime. Where datetime represents a specific point in time, a timespan value represents a duration, down to a second.
While it is useful to think of a date & time as having separate components for each portion, it's more useful to think of a timespan value as just a number of seconds.
Obtaining timespans
Timespans can be obtained by subtracting one date & time from another. In this example, the two points in time are 1 day, 2 hours, 3 minutes and 4 seconds apart:
dp(2022y11M4d10h24m32s) - dp(2022y11M3d8h21m28s)
93784
The resulting timespan is printed as the aforementioned number of seconds, as we can verify by manually calculating the number of seconds in 1 day, 2 hours, 3 minutes and 4 seconds:
1 * 24 * 60 * 60
+
2 * 60 * 60
+
3 * 60
+
4
93784
If we were to swap the order of the two date & time values, the resulting timespan would be negative:
dp(2022y11M3d8h21m28s) - dp(2022y11M4d10h24m32s)
-93784
Formatting timespans using tf()
Timespans can be formatted using tf() (Timespan Format).
There are two main ways to call tf():
-
tf(timespan)- Formats the timespan using a default, human-readable format, -
tf(timespan, format)- Prints the timespan using the given format.
Furthermode, the timespan argument can be a timespan value, or a date & time value. If it is a date & time value, it is first converted to a timespan value by subtracting the current date & time from it.
The default, human-readable format is different depending on whether the first argument was a timespan, or a date & time.
tf(a1h)
60 minutes from now
For timespans, the output will describe the amount of time in the timespan, in the largest units possible. In this example, the timespan is 1 hour (60 minutes * 60 seconds):
tf(60 * 60)
1 hour
For date & time values, the output will describe the given date & time relative to current date & time. In this example, the date & time being given is now + 1 hour:
tf(a1h)
60 minutes from now
As mentioned before, you can pass a format string as the second argument for tf().
Similarly to df(), the format string can contain tokens that will be replaced with values.
Here are all tf() format tokens I know of:
| Token | Meaning |
|---|---|
h |
Hours |
m |
Minutes |
s |
Seconds |
D |
Total days |
H |
Total hours |
M |
Total minutes |
S |
Total seconds |
Consider a timespan lasting 1 day, 2 hours, 3 minutes and 4 seconds.
The values for Hours, Minutes and Seconds are right there - if you used D:hh:mm:ss as the format, you would get 1:02:03:04.
The total number for Days, Hours, Minutes and Seconds is the number of that component plus all previous components converted to the same unit.
Consider minutes for example - the total number of minutes is the number of minutes + number of hours converted to minutes + number of days converted to minutes:
3
+
2 * 60
+
1 * 24 * 60
93784
Therefore, if you used M as the format, you would get 93784.
Because there is no previous component for Days, there is no non-total number of Days, thus the only token for Days is D.
Negative timespans given as date & time values are formatted the same way as positive timespans, but with the word "ago" instead of "from now".
Negative timespans given as timespan values are formatted exactly the same way as positive timespans - there is no sign in the output that the timespan is negative (this might be a bug).
Negative timespans with a custom format print the same way as positive timespans, except the output of each token is prefixed with a minus:
tf(-93784, "D:hh:mm:ss")
-1:-2:-3:-4
hh, mm and ss still pad their respective components with zeroes to two characters,
but in this case the minus sign counts towards the 2 characters, leading to no zeroes being added.
Just like with df() format string, singlequotes can be used to include literal text:
tf(a2h36m, "H
'hours and'
m
'minutes'")
2 hours and 36 minutes
Further reading
If you want to learn more about Kustom:
- Official documentation for all Kustom functions,
- Kustom Discord server, where you can get help and showcase your creations, as well as browse useful resources and formulas created by other users,
- Kustom Subreddit,
- Jagwar's Kustom Basics - tutorial series,
- Brandon Craft's series of tutorials on Kustom apps.
Additional tips & tricks
More about parentheses & quotation marks
Be careful when using parentheses and doublequotes - both will give you errors when mismatched. You need a closing parenthesis for every opening one, and a closing quotation mark for each opening one.
(10 + tc(len, mi(title) + "a"))) * 3
(10 + tc(len, mi(title) + "a")) * 3
Because of that, if you try to put a quotation mark in your string, it'll get treated as a closing quotation mark, which'll break your formula.
"He said "I am dead". He was right."
To get around it, you can use tc(utf).
tc(utf, [character code]) returns a character from its hexadecimal representation.
A doublequote's "hex code" is 22, so tc(utf, 22) will return a doublequote character.
Then, use + to concatenate parts of the string and the doublequotes returned from
tc(utf):
"He said " + tc(utf, 22)
+
"I am dead" + tc(utf, 22) + ". He was right."
He said "I am dead". He was right.
Alternatively, single quotes could be used in the string and later replaced with double quotes using
tc(reg):
tc(reg, "He said 'I am dead'. He was right.", ', tc(utf, 22))
He said "I am dead". He was right.
Concatenating numbers
I mentioned before that I'll present a workaround for concatenating numbers instead of adding them together. It looks like this:
tc(reg, [number 1], "$", [number 2])
This matches the end of the first number and replaces it with the second number. Note that this will still not help you with numeric values written directly:
tc(reg, 003, "$", 009)
39
But, if the number is received from another function and is a text value behind the scenes, it helps avoid the aggressive conversion to number + performs:
tc(lpad, 3, 3, 0) + 9
11
tc(reg, tc(lpad, 3, 3, 0), "$", 9)
0039